前言: 大模型在生成回答的时候,有时总是会词不达意,甚至毫无根据的乱说一通,我们把这种现象称为大模型的幻觉
产生幻觉问题主要是因为其基于大量数据和复杂算法进行概率性预测来生成内容,当遇到训练数据中未充分覆盖或模糊不清的情境时,容易生成看似合理但实际错误或无根据的信息,且难以自我验证内容的真实性 ,然而大模型的生成机制是计算出下一个最有可能出现的词或短语。这种概率生成的方式本身没有绝对的对错判断机制 。**
另外,在实际生产中,还需要面临时效性和可解释性的问题,更具具体业务来生成有针对性的回答,实现这个功能似乎微调能够办到,但是不可能每次有需要更新的内容都微调一次,这样成本太高了
因此我们在大模型中引入RAG技术 ,通过丰富大模型上下文来大幅提高模型输出质量
一、什么是RAG? 通俗点来讲,就是相当于给大模型提供了一个专属图书馆,前期通过数据预处理,把原始文档(PDF、Word、图片等)处理成机器能理解的 “知识片段”,并存储到向量数据库中,在客户向大模型提问(Query)时,大模型通过分析Query,在数据库中检索到与之相关的知识块添加到上下文一起作为prompt传入大模型
R: Retrieval,检索。从外部知识库中检索与当前输入相关的上下文信息A: Augmented,增强。将检索到的上下文信息与模型的内部知识相结合G: Generation,生成。基于增强后的上下文信息生成最终的回答。
精髓在于检索和生成
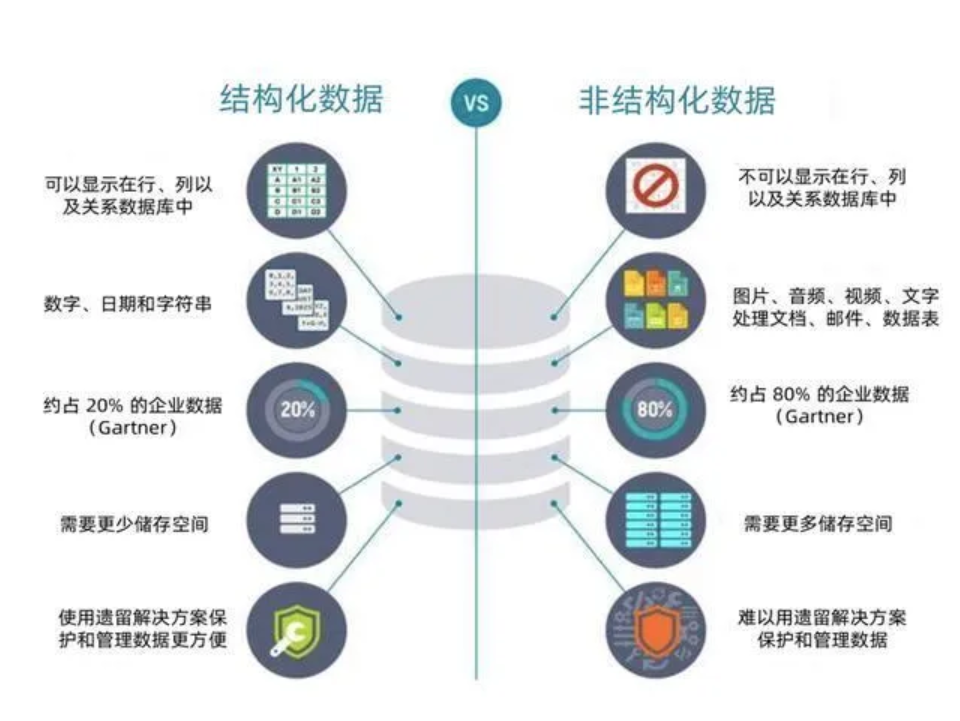
二、RAG实现流程 2.1 构建知识库 2.1.1 读取非结构化数据 实际生产中,会产生一些私有的数据,比如某某公司第一季度财务报表.xlsx、某某产品使用说明书.pdf、员工健康状况分析汇报.png等,这些不像存储在MySQL数据库中的数据那样可以用指令轻易查询修改,他们属于非结构化数据,而RAG主要处理的也就是非结构化数据,将这些各种格式的文档处理成机器可读的文本格式(JSON)
下面这串代码基于langchain,可以处理市面上大多的文档,但是像图片和PDF还需要下载Tesseract-OCR 后才能处理
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 import osimport jsonfrom langchain_community.document_loaders import ( TextLoader, CSVLoader, UnstructuredFileLoader, UnstructuredExcelLoader, PyPDFLoader, ) from PIL import Imageimport pytesseractfrom langchain.schema import Documentfrom tqdm import tqdm def clean_content (text: str ) -> str : """清理文本内容,去掉空格和换行""" return text.replace(" " , "" ).replace("\n" , "" ).strip() def load_documents_from_data_dir (data_dir="./data" ): knowledges = [] all_files = [] for root, _, files in os.walk(data_dir): for file in files: all_files.append(os.path.join(root, file)) for file_path in tqdm(all_files, desc="读取文件进度" , unit="file" ): ext = os.path.splitext(file_path)[1 ].lower() try : if ext == ".txt" : loader = TextLoader(file_path, encoding="utf-8" ) new_docs = loader.load() elif ext == ".csv" : loader = CSVLoader(file_path) new_docs = loader.load() elif ext in [".xls" , ".xlsx" ]: loader = UnstructuredExcelLoader(file_path, mode="elements" ) new_docs = loader.load() elif ext == ".pdf" : loader = PyPDFLoader(file_path) new_docs = loader.load() elif ext == ".md" : loader = UnstructuredFileLoader(file_path) new_docs = loader.load() elif ext in [".png" , ".jpg" , ".jpeg" , ".bmp" ]: text = pytesseract.image_to_string(Image.open (file_path), lang="chi_sim" ) new_docs = [] if text.strip(): new_docs.append(Document(page_content=text, metadata={"source" : file_path})) else : print (f"不支持的文件类型: {file_path} " ) continue for doc in new_docs: doc.page_content = clean_content(doc.page_content) if doc.page_content: knowledges.append({"page_content" : doc.page_content, "metadata" : doc.metadata}) except Exception as e: print (f"读取 {file_path} 失败: {e} " ) return knowledges if __name__ == "__main__" : knowledges = load_documents_from_data_dir("./data" ) print (f"总共读取了 {len (knowledges)} 条知识" ) with open ("knowledges.json" , "w" , encoding="utf-8" ) as f: json.dump(knowledges, f, ensure_ascii=False , indent=4 ) print ("存储完成" )
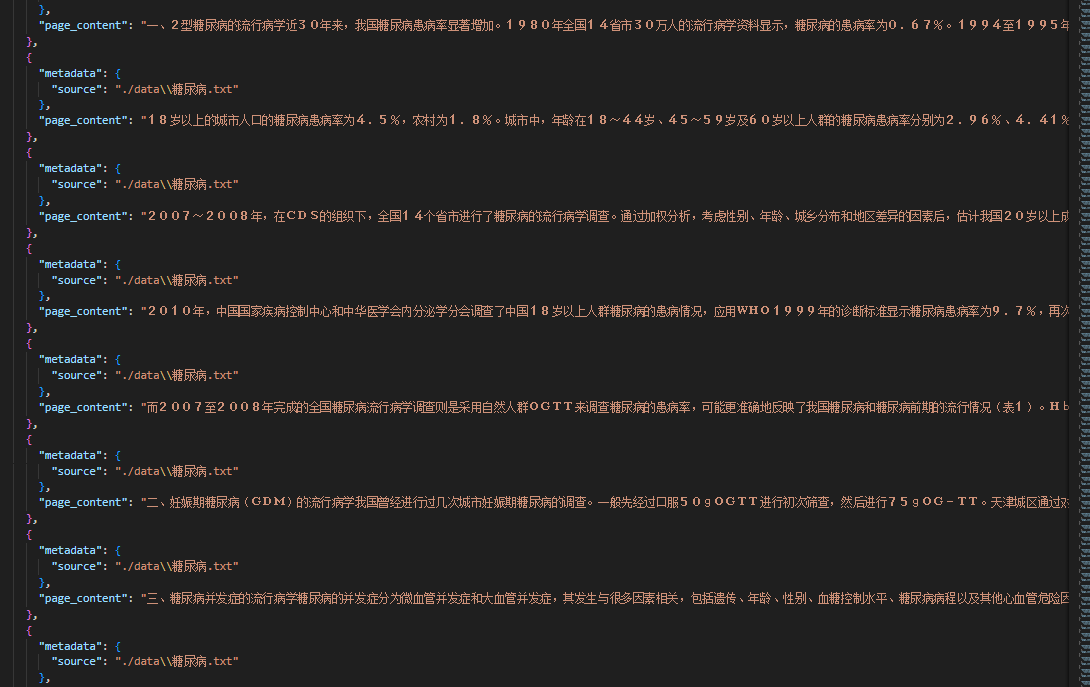
处理后的json文档格式如下图:
那是不是到这里知识库就结束了呢?非也非也
在page_content中存储的是一整个文档的内容,比如一本红楼梦,加入当我想大模型提问“红楼梦的作者是谁”,大模型找到(怎么找到的后面会介绍)这一个知识块传入模型,那就是传了一整本红楼梦进去,这无疑是对大模型上下文推理能力的巨大挑战且没有必要,因为我要的只是“红楼梦的作者是谁”,所以我们还得对知识进行切分
2.1.2 语义分割 这一部分需要一个专门的语义分割大模型(常规大模型也可以,但是没有那么专精),将一个长序列文本切割成一系列独立的知识块
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 from modelscope.outputs import OutputKeysfrom modelscope.pipelines import pipelinefrom modelscope.utils.constant import Tasksimport jsonp = pipeline( task=Tasks.document_segmentation, model='RAG检索增强生成/sentence_cut' , model_revision='master' ) MIN_LEN = 50 with open ('RAG检索增强生成/knowledges.json' , 'r' , encoding='utf-8' ) as f: knowledge = json.load(f) segmented_data = [] for k in knowledge: source = k['metadata' ].get("source" , "" ) text = k['page_content' ].strip() result = p(text) seg_text = result[OutputKeys.TEXT].strip() if '\n' in seg_text: segments = seg_text.split('\n' ) else : segments = [s.strip() for s in seg_text.split('。' ) if s.strip()] merged_segments = [] buffer = "" for seg in segments: if len (buffer) < MIN_LEN: buffer = buffer + "。" + seg if buffer else seg else : merged_segments.append(buffer) buffer = seg if buffer: merged_segments.append(buffer) out = { 'metadata' : source, 'page_content' : "\n" .join(merged_segments) } segmented_data.append(out) print ("==" *20 ) print (source) print (f"分割前段数: {len (segments)} , 合并后段数: {len (merged_segments)} " ) print ("示例段:" , merged_segments[:1 ]) output_knowledge = [] for item in segmented_data: source = item['metadata' ] segments = item['page_content' ].split('\n' ) for seg in segments: output_knowledge.append({ 'metadata' : {'source' : source}, 'page_content' : seg.strip() }) with open ('RAG检索增强生成/knowledges_segmented.json' , 'w' , encoding='utf-8' ) as f: json.dump(output_knowledge, f, ensure_ascii=False , indent=2 )
切割后的结果示例:
这样做不仅能够将长文本切块,还能避免很多在进行数据读取是产生的乱码,这部分就不容易被检索到
2.2 向量数据库存储 向量数据库用于存储文档的向量表示,支持高效的相似度搜索,它的优势就在于检索便捷
提供特定的存储结构和索引算法;
能够高效地存储、查询和处理向量数据
切割的知识块通过词嵌入模型转换为词向量存储到向量数据库,当用户的问题也转化到词向量后,根据余弦相似度等方法来在向量数据库中搜索相关性较大的知识块
常见的三种向量数据库,本质都是一样的,这里我们用Chroma
数据库
优势
劣势
适用场景
FAISS
轻量、开源、检索速度快
无完整数据管理功能(如权限)
本地测试、小规模项目
Milvus
支持大规模数据、分布式
部署复杂、需要一定运维成本
企业级项目、海量数据
Chroma
轻量、支持多模态数据
性能略逊于 Milvus
快速原型开发、中小规模项目
接着上面的知识块来处理
添加:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 import chromadbimport jsonimport hashlibfrom modelscope.outputs import OutputKeysfrom modelscope.pipelines import pipelinefrom modelscope.utils.constant import Tasksfrom chromadb.utils import embedding_functionschroma_client = chromadb.HttpClient(host="127.0.0.1" , port=10221 ) print ("Chroma client:" , chroma_client)model_name = "/root/autodl-tmp/RAG检索增强生成/BAAI-bge-base-zh-v1.5" emb_fn = embedding_functions.SentenceTransformerEmbeddingFunction(model_name=model_name) collection = chroma_client.get_or_create_collection( name="my-collection-decimal" , embedding_function=emb_fn, metadata={"description" : "about company's administration and travel, subsidy, etc." }, ) if __name__ == "__main__" : print ("Collections:" , chroma_client.list_collections()) chunk_min_len = 100 segmenter = pipeline( task=Tasks.document_segmentation, model="RAG检索增强生成/sentence_cut" , model_revision="master" , ) knowledge_path = "RAG检索增强生成/knowledges.json" with open (knowledge_path, "r" , encoding="utf-8" ) as f: knowledge = json.load(f) ids, documents, metadatas = [], [], [] for k in knowledge: print ("=" * 60 ) source_value = k.get("metadata" , {}).get("source" , "" ) print (f"Source: {source_value} " ) result = segmenter(documents=k["page_content" ]) chunks = [c.strip() for c in result[OutputKeys.TEXT].strip().split("\n" ) if c.strip()] tmp = "" for chunk in chunks: tmp += chunk if len (tmp) >= chunk_min_len: doc_id = hashlib.md5(tmp.encode("utf-8" )).hexdigest() existing = collection.get(ids=[doc_id]) if existing["ids" ] or doc_id in ids: tmp = "" continue ids.append(doc_id) documents.append(tmp) metadatas.append({"source" : source_value}) tmp = "" if tmp: doc_id = hashlib.md5(tmp.encode("utf-8" )).hexdigest() existing = collection.get(ids=[doc_id]) if not existing["ids" ] and doc_id not in ids: ids.append(doc_id) documents.append(tmp) metadatas.append({"source" : source_value}) collection.add(ids=ids, documents=documents, metadatas=metadatas) print ("知识块添加成功,总数量:" , collection.count())
2.3 查询相关知识块 这一步主要是进行一轮初筛,把相关的都拿出来
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 import chromadbchroma_client = chromadb.HttpClient(host="127.0.0.1" , port=10221 ) collections = chroma_client.list_collections() collection = chroma_client.get_collection(name="my-collection-decimal" ) results =collection.query( query_texts=["孙悟空有几条命" ], n_results=5 ) print ("=" *50 )print ('搜索到的知识块:' , results['documents' ])print ("=" *50 )print ('搜索到的知识块的向量距离:' , results['distances' ])print ("=" *50 )print ('搜索到的知识块的id:' , results['ids' ])print ("=" *50 )print ('搜索到的知识块的元数据:' , results['metadatas' ])
2.4 重排序Rerank 这一步是使用重排序的rerank模型对检索到的知识块进行一个相关性排序,把相关性高的放前面,这样大模型在分析上下文的时候更容易捕捉到细节
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 import chromadbimport requestschroma_client = chromadb.HttpClient(host="127.0.0.1" , port=10221 ) collections = chroma_client.list_collections() collection = chroma_client.get_collection(name="my-collection-decimal" ) Question = "孙悟空有几条命" results =collection.query( query_texts=[Question], n_results=5 ) url = "http://127.0.0.1:10220/rerank" data = { "model" :"/root/autodl-tmp/RAG检索增强生成/bge-reranker-base" , "query" :Question, "documents" :results['documents' ][0 ] } response = requests.post(url, json=data) print (response.json())
最后把检索重排序到的参考文献添加到prompt中,大模型就可以有依据的生成内容了