
探究通过各种绕过网易易盾人工验证的方法
前言:
在网络安全与情报分析工作中,自动化抓取互联网信息成为关键手段。然而,越来越多网站为防范爬虫和批量操作,部署了多样化、高难度的人工验证机制,包括滑块拼图、汉字点选、障碍躲避等类型。这些验证码不仅包含图形干扰,还融入语义理解(如“点击包含交通标志的图片”)、逻辑判断(如“按成语顺序点选汉字”)甚至动态行为分析,使得传统的自动化绕过方法(如基于 OpenCV 的模板匹配、OCR 识别)难以应对——前者在面对旋转、变形、动态干扰时失效,后者在复杂背景或非标准字体下识别率骤降。
为突破这一瓶颈,本文聚焦于滑块验证(含旋转干扰)、文字点选(成语/顺序类)与障碍躲避三类典型验证码,调研基于视觉语言大模型的智能识别与交互新方法。通过结合Playwright与多模态大模型的语义理解能力,构建了一套能理解验证任务语义、定位目标元素、模拟人类操作的自动化流程。
对于高度动态、行为特征强绑定(如鼠标轨迹分析)或需上下文记忆的验证形式,当前方法仍存在局限,需进一步融合行为模拟与上下文推理能力。
一个自动化登录的demo

一、VL大模型
1.1 定义
视觉-语言大模型(Vision-Language Models, VLMs)从本质上来说就是给大语言模型(LLM)加上了一双眼睛,让LLM能有感知视觉的能力,是结合视觉(图像/视频)和语言(文本)处理能力的多模态人工智能模型,能够理解并生成与视觉内容相关的自然语言。

1.2 核心组件
- 视觉编码器:负责提取图像特征
- 语言编码器/解码器:处理文本信息
- 跨模态融合模块:实现视觉和语言特征的深度融合
VL模型作为视觉模型和自然语言模型的融合,它接收图像及其相应的文本描述作为输入。 这类模型不仅能够解释视觉内容,还能生成相关的自然语言描述,实现真正的多模态交互。
1.3 大模型理解图像的流程
其实VLM的原理和LLM是一样的,都是把用户的输入通过embedding转换成tokens输入到模型进行计算
VL大模型之所以能理解图片,本质上是通过深度神经网络提取视觉特征,投影层实现跨模态对齐,大语言模型进行语义融合和推理的三步走策略。它不是真的”看”图片,而是通过数学向量在高维空间中建立视觉和语言的对应关系,从而实现对图像内容的理解和描述。
1.3.1 图像预处理阶段
当一张图片输入到VL大模型时,首先会经过标准化处理:
- 调整尺寸(通常为224×224或448×448像素)
- 归一化像素值
- 分割成固定大小的图像块(patches)
1.3.2 特征提取阶段
视觉编码器对预处理后的图像进行深度特征提取:
- 低层特征:边缘、纹理、颜色等基础视觉信息
- 中层特征:物体部件、简单形状等
- 高层特征:语义信息、物体类别、场景理解等
- 空间关系:通过自注意力机制捕捉图像中不同区域之间的关系
1.3.3 跨模态对齐阶段
这是VL大模型理解图像的核心机制:
特征空间对齐:
- 视觉特征和文本特征被映射到同一个语义空间
- 例如,当看到”狗”这个词和一张狗的图片时,它们的向量表示在空间中会很接近
- 这种对齐是通过对比学习等训练方法实现的
语义理解融合:
- 投影后的视觉token和文本token一起输入到大语言模型
- LLM通过自注意力机制同时处理视觉和语言信息
- 模型能够建立”图像区域-文本描述”之间的细粒度对应关系
1.4 图解各个部分处理流程
1.4.1 图像预处理阶段
1 | flowchart TD |
1.4.2视觉特征提取阶段
1 | flowchart TD |
1.4.3 跨模态对齐阶段
1 | flowchart TD |
1.4.4 多模态融合与输入构建阶段
1 | flowchart TD |
1.4.5大语言模型处理与推理阶段
1 | flowchart TD |
在此基础上,可以使用VLM来帮助程序判断识别,例如应该将滑块移动到移动到哪个位置,或者在进行汉字点选时应该按照什么顺序,点击什么位置
1.5 常见人工验证方式
1.5.1 简单点击验证
没有其他的验证操作,直接点击对应区域即可,可以直接交由PlayWright来操作
1.5.2 拖动滑块验证
平移拼图
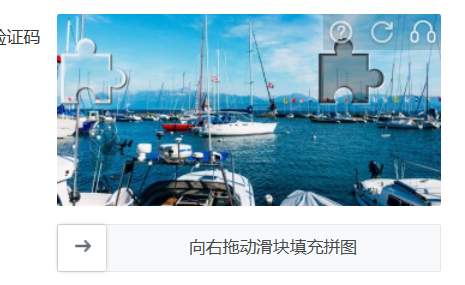
拖动滑块后拼图会转动

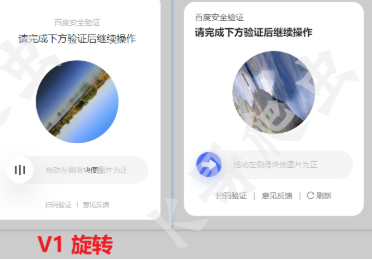
两个思路:OpenCV,VLM
第一个思路:使用OpenCV进行模式识别,可以直接按照滑块的形状和缺口中的形状来进行匹配,从而判断滑块应该移动多少像素位置
实现方法:从网页HTML中找到构成滑块验证的两个部分:滑块和带缺口的背景图,使用下面代码进行模版匹配并逐像素比较每个位置的相似度(offset = 背景中最匹配滑块缺口的左上角横坐标),匹配位置的 x 坐标(max_loc[0]) 就是滑块验证码所需的 移动像素偏移量。
1 | import cv2 |
缺陷:对于带旋转的滑块验证,这种逐一比对的方法就不适用了,因为此方法只能固定从左到右去平移来匹配(当然可以考虑在平移过程中加上旋转,但是这样如果后面有其他情况有需要考虑代码修改),因此下面提出第二种方法:使用大模型来判断滑块是否滑动到位
第二个思路:使用VLM+提示词,当用户每次滑动一段距离,进行页面截图传回给VLM,由VLM来判断是否到位,针对性的进行微调,这样能够适应大部分滑块验证场景,不用考虑旋转等问题
简单在Qwen中示例:


1.5.3 点选文字验证
按照顺序点选

按照能否组成四字成语点选

对于点选式验证码的问题,我们可以将其拆解为两个小问题:
1、确定需要点击的字的数量和位置: 对于点选式验证码,准确识别和定位需要点击的字的数量和位置是解决问题的关键。 其中,一种常见的目标检测算法是 YOLO,通过标注数据集和训练模型,可以实现对需要点击的字进行准确识别和定位。
2、对点击的字进行排序: 在确定出需要点击的字的位置后,需要按照一定的规则对这些字进行排序。采用传统的方案是通过识别图片中的文字,然后按照文字位置进行排序,但这种方法训练困难。因此,本项目采用了图片匹配模型,使用 Siamese 孪生网络对需要点击的字与预先准备好的字库中的字进行匹配,找到最佳匹配的字,并按照一定的规则进行排序。Siamese 孪生网络在图像匹配方面表现优异,能够有效地提高排序的准确性和稳定性。
尝试用三种方案来实现:OCR、VLM、YOLO+Siamese孪生网络
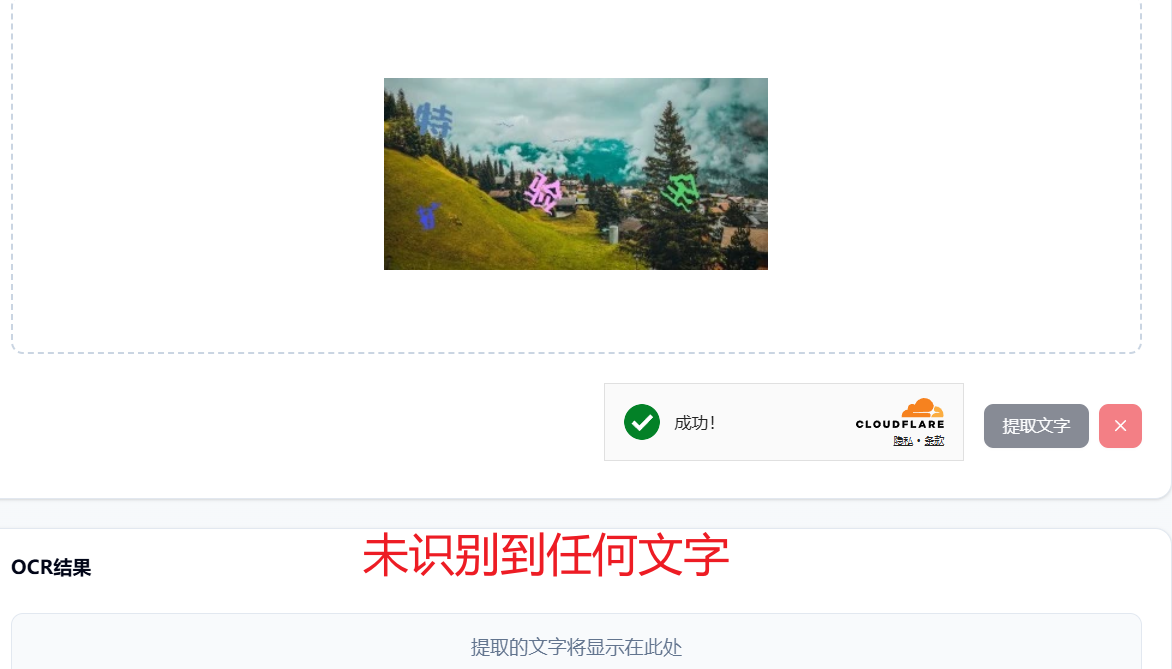
OCR(失败):
OCR能识别文字,是因为它通过图像预处理提升文字清晰度,再利用文本检测定位图像中的文字区域,接着通过字符分割(或端到端深度学习模型)将图像中的字符转化为机器可理解的特征,最后借助分类器或神经网络识别出对应的文字,并结合语言模型进行后处理纠错,从而实现从图像到可编辑文本的转换。
由于复杂的背景和颜色融合综合程度较深,OCR无法有效提取到文本进行后续操作,导致识别失败
VLM(成功,但是仍然会存在识别不出来或者坐标偏差大的情况):
使用VLM+提示词,将识别目标坐标以json格式输出,再后续操作进行解析即可操作
调整 “temperature”: 0,”top_k”: 1两个参数,保障每次输出结果稳定
优化方案:通过修改提示词可以优化识别效果,但是不同场景下同一套提示词可能效果偏差会比较大
1 | import base64 |
可以看到虽然效果会比OCR提升很多,但是仍然存在偏差,考录还是背景太复杂的原因

YOLO+Siamese孪生网络(成功,且对一般目标效果较好)
项目地址:Text_select_captcha
yolov5训练过程:
训练流程一般包括如下几个步骤:获取训练数据集、数据预处理、模型选择、设置损失函数、反向传播和更新权值等。
使用lambeling标注char和target

接下来是选择合适的模型。YOLO 系列模型有多个版本,可以根据不同的需求选择适合的版本。选择好模型后,需要设置损失函数和训练参数,进行模型训练。
YOLO检测结果

使用孪生网络进行图像检索任务的训练前,需要对数据集进行准备。与其他模型不同,孪生网络的训练需要用到正负样本对,因此需要对数据集中的每张图像都生成一些与之匹配和不匹配的样本对。
具体实现时,一般采用已经训练好的检测模型来生成样本对。
具体操作流程如下:首先,使用检测模型对数据集中的图像进行检测,截取出每个目标的图像片段;然后,把该图像片段分别与数据集中的其他目标进行匹配和不匹配的组合,形成匹配和不匹配的样本对;最后,根据样本对的匹配情况对其进行标注,将匹配和不匹配的样本对分别放到不同的文件夹中,按照类别和顺序标注好,方便后续使用。
如下图所示,每张图像都会对应一个匹配和不匹配的样本对,每个样本对包含两张图像,分别作为孪生网络的输入。
孪生网络标注结果

孪生网络识别结果:

如图所示,孪生网络输出的结果可以给出背景图中的目标与右下角的目标最相似的结果,而左下角的目标则可以通过按照左坐标进行排序来得到。由此,可以方便地得到背景图中所有目标的顺序。
识别效果:
根据页面截图降低分辨率后仍然可以检测到目标,并且判断点击顺序

1.5.4 躲避障碍

实现方案:将图片转灰度+VLM+路径设计算法
首先调用多模态大模型对输入图像进行分析,自动识别出其中所有与背景明显区分的漂浮图标,并输出每个图标的相对坐标、中心点和大小;随后将识别结果转换为像素坐标,在图像上绘制标注。接着,程序以左下角为起点、指定图标为目标点,利用人工势场法模拟小球运动,通过计算目标的吸引力和图标的排斥力,使小球在避开障碍物的同时逐步接近目标点,当到达目标区域后停止运动,最终生成带有路径轨迹的图像输出。
1 | import requests |

